

大数据概述
发布时间:2021-2-24 14:30阅读:898
 问一问
问一问1.1 大数据概述
数据在以越来越快的速度不断增长。移动电话、社交媒体和用于医疗诊断的影像技术等新业务,每天都会产生大量的新数据,这些数据都需要存储到起来供日后使用。此外,设备和传感器自动生成的诊断信息也需要得到实时存储和处理。应对如此庞大的数据涌入不是一件很容易的事情,更具挑战的是如何分析这些海量数据,尤其是当这些数据不是传统的结构化数据时,如何才能识别有意义的模式,并且提取有用的信息呢?这些海量数据带来了许多挑战,同时也为改变商业、政府、科学和人们的日常生活带来了可能。
下面几个行业在收集和利用数据方面做的非常出色。
- 信用卡公司监控其用户的每一笔交易,并使用从数十亿笔业务的处理中获得的规则,相当精准地识别欺诈交易。
- 移动运营商分析用户的呼叫模式,能够判断哪些用户经常和其他移动运营商的用户联系。为了避免竞争对手通过低价合同来吸引自己的用户,运营商可以预先为这些用户提供奖励,以防止用户流失。
- 对于LinkedIn和Facebook这类公司,数据本身就是其主要的产品。这些公司的估值很大部分源于他们收集和托管的数据,随着数据的增长,这些数据的内在价值也会越来越多。
具体来说,大数据具有3个基本特征。
- 数据体量巨大:大数据的数据体量远不止成千上万行,而是动辄几十亿行,数百万列。
- 数据类型和结构复杂:大数据反映了各种各样新的数据源、数据格式和数据结构,包括网页上留下的数字痕迹和可供后续分析的其他数字资料库。
- 新数据的创建和增长速度:大数据能够描述高速数据,快速地采集数据和近乎实时地分析数据。
尽管大数据的体量最受人们关注,通常来讲,数据的种类和速度却能更贴切地定义大数据(业界将大数据归纳为3个V:数量[Volume]、种类[Variety]和速度[Velocity])。由于其数据结构和数据规模的特点,使用传统的数据库或方法已经很难有效地分析大数据了。因此,我们需要新的工具和技术来存储、管理和实现其商业价值。这些新的工具和技术能够创建、操纵、管理大型数据集和用来存储数据集的存储环境。2011年,麦肯锡发布的全球报告给大数据下了一个定义:
大数据是具有大规模、分布式、多样性和/或时效性的数据,这些特点决定了必须采用新的技术架构和分析方法才能有效地挖掘这些新资源的商业价值。
麦肯锡公司《Big Data: The Next Frontier for Innovation, Competition, and Productivity》[1]
麦肯锡对大数据的定义表明,公司需要新的数据架构和分析沙盘、新的工具、新的分析方法,以及将多种技能整合到数据科学家的新角色中(这将在1.3节将详细讲解)。图1.1列举了大数据洪流的几个主要来源。

图1.1 大数据洪流的几个主要来源
从图1.1中所列的几个来源可见,数据创造的速度正在加快。
大数据中增长最快的数据源是社交媒体和基因测序,它们也是非传统的被用来分析的数据源。
例如,在2012年,Facebook全球用户每秒钟会发布700条状态更新,通过分析这些状态更新信息就可以判断出用户的政治观点和潜在的兴趣产品,从而有针对性地向用户投放广告。比方说,如果某位Facebook女性用户将自己的感情状况从“单身”改为“定婚”,那么就可以有针对性地向这位用户投放婚纱礼服、婚礼策划或更改名称这类服务的广告。
Facebook还可以通过构建社交图来分析用户彼此之间的互联关系。在2013年3月,Facebook就发布了一项名叫“搜图“(Graph Search)的新功能,用户和开发人员可以使用该功能来搜索兴趣、爱好和共享位置相似的用户群。
基因组学也有成功利用大数据的例子。基因测序和人类基因图谱有助于科学家深入了解人类基因的构成和血统。此外,医疗保健行业也正在试图预测人的一生中容易生的疾病,然后使用个性化的医疗方法来预防这些疾病或减轻这些疾病的影响。这类测试也会标记不同药物和医疗用药的反应,以提高特殊药物治疗的风险意识。
虽然数据增长很快,但是执行数据分析的成本却在急剧下降。2001年为人类基因测序的成本要1亿美金,到2011年该项费用只需1万美元,目前该费用还在持续下降。现在,在23andme(见图1.2)这样的网站上进行基因分型(genotyping)只需要不到100美元。虽然基因分型只是分析基因组的一小部分,并且没有基因测序那么细的分析粒度,但还是可以佐证一个事实,那就是数据和复杂的分析正在变得越来越普遍,而且越来越便宜。
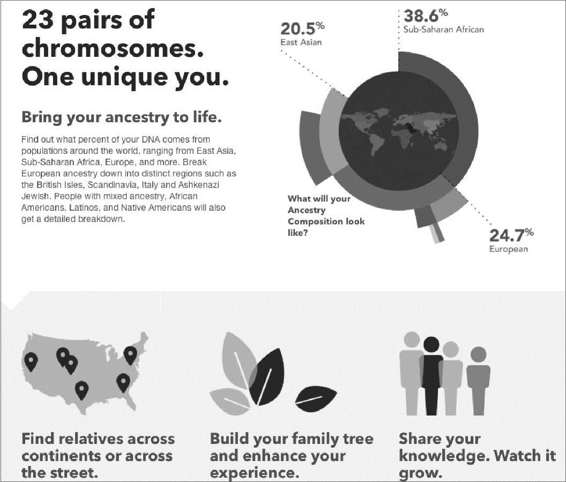
图1.2 通过基因分型可以学到什么,源于网站23andme.com
社交媒体和基因测序的例子表明,个人和组织都会从分析更为庞大和复杂的数据中受益,而分析这些数据则需要更加强大的分析性能。
1.1.1 数据结构
大数据可以有多种形式,包括结构化数据和类似财务数据、文本文件、多媒体文件和基因定位图这样的非结构化数据。不同于传统数据分析,绝大多数的大数据天生是非结构化数据或者半结构化的数据,因而需要被有别于传统的技术和工具来处理和分析[2]。分布式计算环境和大规模并行处理(MPP)架构让数据的并行化采集和分析成为处理这些复杂数据的首选方法。
鉴于此,本节将继续讲解数据的结构。
图1.3中列出了数据结构的4种类型,未来80%~90%的增长数据都将是非结构化数据类型[2]。虽然从结构上看数据可以被分成四种类型,可是大部分的数据都是混合类型。例如,一个典型的关系型数据库管理系统(RDBMS)可能存储着软件支持呼叫中心的呼叫日志。RDMBS可能将呼叫的特征存储为典型的结构化数据,它具有时间戳、机器类型、问题类型和操作系统等属性。此外,该系统也可能存储着非结构化、准结构化或者半结构化数据,例如,从电子邮件故障单、客户聊天历史记录、用来描述技术问题和解决方案的通话记录,以及客户通话语音文件中提取出来的自由格式的呼叫日志信息。从呼叫中心的非结构化、准结构化或半结构化数据中可以提取甚多洞见。
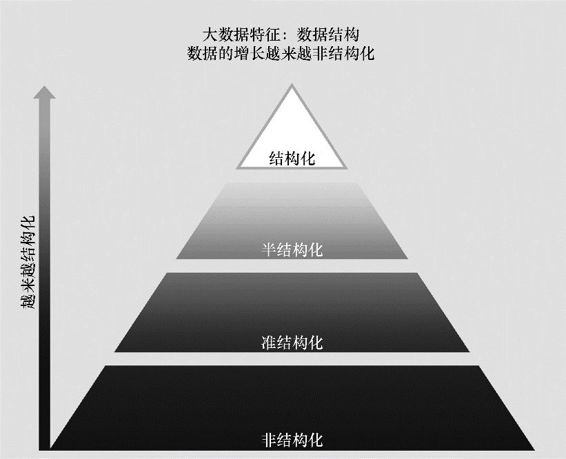
图1.3 大数据的增长越来越非结构化
虽然结构化数据的分析技术已经非常成熟,但是我们还是需要不同的技术来应对半结构化数据(比如XML格式)、准结构化数据(比如点击流)和非结构化数据分析所带来的新挑战。
下面给出了4种主要数据结构类型的定义和例子。
- 结构化数据:数据包括预定义的数据类型、数据格式和数据结构(例如交易数据、在线分析处理[OLAP]数据集、传统的RDMBS、CSV文件甚至电子表格)。详细信息参考图1.4。

图1.4 结构化数据示例
- 半结构化数据:有识别模式的文本数据文件,支持语法分析(例如,有模式定义的和自描述的可扩展标记语言[XML]数据文件)。详细信息参考图1.5。
- 准结构化数据:这类文本数据带有不规则的数据格式,但是可以通过工具规则化(例如,可能包含不一致的数据值和格式的网页点击流数据)。详细情况可参考图1.6。
- 非结构化数据:数据没有固有的结构,例如文本文件、PDF文件、图像和视频。详细情况可参考图1.7。
准结构化数据是一种被极大关注的常见数据类型。让我们看看下面这个示例。如果一位用户参加了一年一度的EMC WORLD大会,然后在网上使用谷歌搜索引擎来查找EMC与数据科学相关的信息。这样就产生了一个类似https://www.google.com/#q=EMC+ data+science的URL地址和结果列表,如图1.5中第1张图所示。
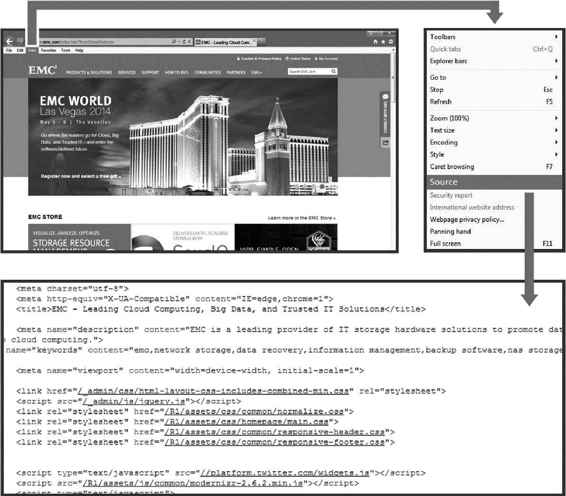
图1.5 半结构化数据示例
在搜索之后,用户通过访问第2个链接地址,就可以获得更多“数据科学家——EMC教育、培训和认证”的相关内容。这会将用户带到关注该主题的一个emc.com站点以及一个新的URL:https://education.emc.com/guest/campaign/data_science.aspx,如图1.6中第2张图片所示。在该网站,用户还可以了解到数据科学认证的相关流程。通过点击认证页面顶部的链接,就可以访问一个新的URL地址:https://education.emc.com/guest/certification/framework/stf/data_science.aspx,如图1.6中第3张图所示。
访问上述3个网站就增加了3个URL地址到日志文件,该日志文件用于监控用户计算机或者网络的使用情况。这3个URL网址分别如下所示。
https://www.google.com/#q=EMC+data+science
https://education.emc.com/guest/campaign/data_science.aspx
https://education.emc.com/guest/certification/framework/stf/data_science.aspx

图1.6 EMC数据科学搜索结果的示例

图1.7 非结构化数据示例:南极科考相关视频[3]
这3个URL组反映了查找EMC相关的数据科学信息的网站和操作。因此,数据科学家通过分析和挖掘相关的点击流,可以发现使用模式,揭开点击之间的关系,以及一个或一组网站上的热点区域。
本节介绍的四种数据类型有时被归纳为二类:结构化数据和非结构化数据。而大多数组织机构并不习惯处理大数据,特别是那些非结构化数据。因此,下一节将从大数据分析的角度介绍一些常用的技术架构。
1.1.2 数据存储的分析视角
电子表格赋予数据行和列的结构,使得商业用户可以在数据的行和列结构上创建简单的逻辑,从而创建针对业务问题的分析。创建电子表格非常方便快速,并不需要专门的数据库管理员培训。电子表格非常便于分享,用户可以控制所涉及的逻辑。然而,它们的扩散会导致“真相有许多版本”。换句话说,我们很难确定某个特定用户是否拥有最相关的电子表格版本(其中具有最新的数据和逻辑)。而且,笔记本丢失或者文件损坏都可能会造成电子表格内数据和逻辑的丢失。在世界上的许多计算机中都运行着电子表格程序(比如Microsoft Excel),所以这个挑战将持续存在。随着数据岛的增加,数据集中化的需求比以往任何时候都要更加迫切。
随着数据需求的增长,更多可扩展的数据仓库解决方案出现了。这些技术使得数据可以被集中管理,可以提供安全性、故障切换和单一存储仓库,用户可以从中获取到“官方”数据用于财务报表或者其他关键任务。单一数据存储仓库也便于创建OLAP多维数据集和商业智能分析工具,可以用来快速访问关系型数据库管理系统内的一组数据维度。此外,更多的高级功能提供了高性能的深入分析技术,比如回归和神经网络。企业数据仓库(EDW)对于报表和商业智能任务都非常关键,能够解决电子表格增生(proliferating)所引起的许多问题,比如在具有多个版本的电子表格中,无法确定哪一个版本是正确的。EDW和良好的商业智能战略从集中管理、备份和保护的数据源中提供了直接的数据提要(data feed)。
虽然企业数据存储库和商业智能有许多优点,但是它们都会限制在执行健壮的和探索性数据分析时所需要的灵活性。在EDW模型中,IT部门或者数据库管理员(DBA)管理和控制数据,数据分析员必须通过IT部门来访问和修改数据模式。这会导致分析员花费更长的时间来获得数据,大量的时间都浪费在等待审批这类没有意义的工作上。此外,大多数情况下,EDW的规则都会限制分析员构建数据集。因此,经常会用到额外的系统,该系统包含用来构建分析数据集的关键数据,并且由用户在本地管理。一般情况下,IT部门都不喜欢无法控制的数据源,因为不像EDW,这些数据集是不受管理的,而且也没有保护和备份。在分析员看来,EDW和商业智能解决了数据准确性和可用性的问题,但是也带来了灵活性和敏捷性相关的新问题,这些问题在处理电子表格的时候并不明显。
分析沙盘(analytic sandbox)是解决这个问题的一种方法,它试图解决分析员、数据科学家与EDW、严格管理的企业数据之间的冲突。在此模式下,IT部门仍然管理分析沙盘,但是沙盘将进行有针对性的设计,以启用强大的分析能力,同时还能被集中管理和保护。沙盘也被称为工作区,旨在使团队以一种受控的方式来探索更多数据集,通常不用于企业级的财务报表和销售报告。
很多时候,分析沙盘利用数据库内处理(in-database processing)式的高性能计算——分析都是在数据库内部进行。在数据库内部运行分析可以提供更好的分析性能,因为省去了将数据拷贝到位于其他某地的分析工具的步骤。数据库内分析(将在第11章进一步讨论)创建同一组织的多个数据源之间的关联,节省了以个体为基础创建这些数据提要的时间。用于深入分析的数据库处理加速了开发和执行一个新分析模型所用的周转时间,同时减少(但是没有消除)了与存放在本地“影子”文件系统中的数据相关的成本。此外,不同于EDW中典型的结构化数据,分析沙盘可以容纳更多样性的数据,比如,原始数据、文本数据和其他类型的非结构化数据,而且不会与关键的生产数据库形成干扰。表1.1简要地描述了本节提到的数据存储库的特征。
表1.1 数据存储库的类型(站在分析员的角度)

在大数据分析项目中,需要考虑几件事情以确保方法与预期的目标相匹配。由于大数据所具有的特征,这些项目长常用于为高价值但是处理复杂度较高的战略决策提供支持。由于数据量相当大,结构较为复杂,所以在这种环境中使用的技术必须具备迭代性(iterative)和灵活性。快速且复杂的数据分析需要高吞吐量的网络连接,并考虑一个可接受的延迟量。例如,开发一款用于网站的实时产品推荐系统比开发一款近实时推荐系统需要更高的系统需求,因为近实时推荐系统在提供可接受的性能的同时,延迟只是稍大一点点,但是部署成本更低。我们需要使用不同的方法来应对分析中的挑战,下一节将继续讨论这个主题。
温馨提示:投资有风险,选择需谨慎。

 +微信
+微信
 当前我在线
最快30秒解答
当前我在线
最快30秒解答
文章很精彩?转发给需要的朋友吧 
 分享该文章
分享该文章
















-
想换券商又怕麻烦?转户全流程拆解:不用先销户,资产转移比你想象的简单
 2026-07-13 10:11
2026-07-13 10:11
-
104天过会、估值420亿:宇树科技凭什么成为"人形机器人第一股"?
2026-07-13 10:11
-
本周打新日历:2026年A股规模最大IPO【长鑫科技】即将发行!一键速览重点
2026-07-13 10:11


