

第3阶段:模型规划
发布时间:2021-2-24 16:49阅读:601
 问一问
问一问2.4 第3阶段:模型规划
弘业期货徐经理18843102653(同微信)QQ774973294
本资讯仅供参考,据此入市,风险自担
在第3阶段,如图2.5所示,数据科学团队需要确定要应用到数据上的候选模型,以便根据项目的目标进行数据聚类、数据分类,或者发现数据间的关系。团队在第1阶段时通过熟悉数据和理解业务问题或领域而形成的关于数据的初始假设,会在本阶段得以应用。这些假设有助于团队设定要在第4阶段执行的分析,以及选择正确的方法来实现分析目标。
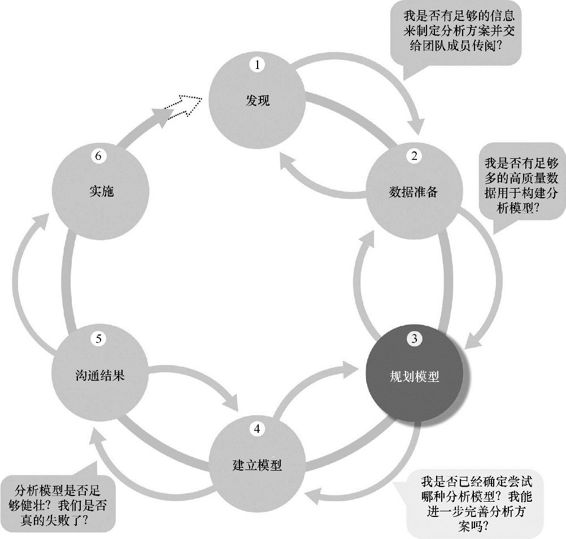
图2.5 模型规划阶段
以下是这个阶段可以考虑的几项活动。
- 评估数据集的结构。数据集的结构是决定下一阶段使用的工具和分析技术的一个重要因素。比如分析文本数据和分析交易数据需要使用不同的工具和方法。
- 确保分析技术能够使得团队达成业务目标,验证或否定工作假设。
- 确定使用单个模型还是一系列技术作为分析工作流的一部分。一些示例模型包括关联规则(第5章)和逻辑回归(第6章)。其他工具,比如Alpine Miner,让用户可以建立一系列分析步骤,可以作为前端用户界面(UI)在PostgreSQL中操控大数据源。
除了上面列出的考量之外,研究和了解其他数据分析师大概如何解决一些特定问题也是非常有用的。根据给定的数据种类和资源,评估是否有相似的现成的可用方法,还是需要创建新的方法。通过学习别人在不同的垂直行业和领域解决类似问题的方法,团队经常可以获得许多灵感。表2.2总结了若干垂直行业,和之前用于相关业务领域的分类模型和技术。通过这些工作可以让团队了解到别人如何解决类似的问题,为团队在模型规划阶段提供一系列的候选模型。
表2.2 垂直行业中模型规划的研究

2.4.1 数据探索和变量选择
虽然有些数据探索发生在数据准备阶段,但是这些活动主要集中在数据卫生(data hygiene)和评估数据本身的质量。在第3阶段,数据探索的目标是理解变量之间的关系,以便决定变量的选择和方法,并了解问题领域。同数据分析生命周期的早期阶段一样,花费时间并集中注意力在数据探索这一准备性工作非常重要,可以让随后的模型选择和执行更加容易和有效。使用工具进行数据可视化是数据探索的常用手段,有助于团队在较高的层次上预览数据和评估变量之间的关系。
在许多情况下,利益相关者和领域专家知道数据科学团队应该考虑和分析什么样的数据。他们的某些猜测甚至可能导致了项目的起源。通常情况下,利益相关者对问题和业务非常了解,尽管他们可能不了解数据的细微之处,或者用于验证或否定一个假设所需要的模型。在其他时候,利益相关者可能是正确的,但是是基于错误的原因(例如,他们可能知道一种现存的关联关系,但是却为这种关联关系推断出了一个错误的原因)。同时,数据科学家必须用一种客观的思维方式来考虑问题,并准备质疑所有假设。
随着团队开始质疑到来的假设并检验项目发起人和利益相关者的一些初始想法,他们需要考虑输入和需要的数据,然后必须检查这些输入数据是否与项目计划预测或分析的结果存在关联性。某些方法和模型类型比其他方法能够更好地处理相关变量。依据试图解决的问题,团队可能需要通过考虑替换方法,减少数据输入的数量,或转换输入来寻找应对给定业务问题的最佳方法。这些技术将在第3章和第6章进一步探讨。
这种方法的关键是捕捉最本质的预测因子(predictor)和变量,而不是考虑人们认为可能影响到结果的每一个变量。以这种方式着手处理问题需要迭代和测试来识别最本质的用于分析的变量。团队应该计划测试在模型中的一系列变量,然后专注于最重要和最具影响力的变量。
如果团队计划运行回归分析,需要确定模型的候选预测因子和结果变量。需要计划创建能决定结果的变量,而且该变量能表现出与结果而不是其他输入变量具有强关联。对于能干扰这些模型的有效性的问题,比如序列相关性、多重共线性,以及其他典型数据建模的挑战,要保持警惕。有时,通过重塑一个给定问题就能避免这些问题。另外,有时候需要做的就是确定相关性(“黑盒预测”),而在其他情况下,项目的目标是更好地理解因果关系。 在后一种情况下,团队希望模型有解释力,而且需要在不同的情况下使用不同的数据集来预测模型或对模型进行压力测试。
2.4.2 模型的选择
在模型选择的子阶段,团队的主要目标是基于项目的最终目标来选择一种分析技术,或者一系列候选技术。在本书中,模型是一种泛指。在这种情况下,一个模型指的是对现实的一种抽象。人们观察到事件发生在真实场景中,或者带有实时数据,然后试图通过一组规则和条件来构建模仿这种行为的模型。就机器学习和数据挖掘而言,这些规则和条件一般分为若干类技术,比如分类、关联规则和聚类。有了这些潜在的模型类别,团队可以过滤出几个可行的模型,以尝试解决一个给定问题。第3章和第4章中将介绍更多为常见业务问题匹配模型的细节。
在处理大数据时需要额外考虑的是确定团队是否将使用最合适的技术处理结构化数据、非结构化数据或混合数据。例如,团队可以利用MapReduce分析非结构化数据,这将在第10章重点介绍。最后,团队应该注意鉴别和记录自己所做的用来选择构建初始模型的建模假设。
通常,团队使用统计软件包(例如,R、SAS或Matlab)来创建初始模型。虽然这些工具为数据挖掘和机器学习算法而设计,但是在将模型应用到非常大的数据集时(这在大数据中很常见),这些工具可能会有局限性。在这种情况下,当团队进行到生命周期第6阶段提及的试点阶段,可能会考虑重新设计这些算法,以在数据库中运行。
一旦决定了要尝试的模型类型,而且已经具备了足够的知识来细化分析计划,团队就可以进入到模型建立阶段。在进入这个阶段之前,需要建立关于分析模型的通用方法论、对要使用的变量和技术有深刻的理解,以及有关于分析流程的描述或图表。
2.4.3 模型设计阶段的常用工具
许多工具可以在这个阶段使用。以下是几种常见的工具。
- R[14]有一套完整的建模能力,提供了一个良好的环境来构建具有高质量代码的解释模型。此外,它还能通过ODBC连接与数据库交互,并通过开源扩展包对大数据进行统计测试和分析。这两个特点使得R非常适合对大数据执行统计检验和分析。在本书写作时,R包含近5000个用于数据分析和图形展示的扩展包。R的新包发布很频繁,而很多公司提供关于R的增值服务(比如,培训、指导和最佳实践),并对它进行打包,使得它更加容易使用和更加健壮。类似的现象在1980年代末和1990年代初曾发生在Linux身上,当时很多公司对Linux进行打包,以使Linux更加容易被公司使用和部署。R和文件提取配合使用可以实现最佳性能的离线分析,而R和ODBC连接配合使用可以实现动态查询和更快地开发。
- SQL Analysis services[15]可以执行数据库内分析实现常见数据挖掘功能,包括聚合和基本预测模型。
- SAS/ACCESS[16]通过多种数据连接(比如,OBDC、JDBC和OLE DB)提供SAS和分析沙箱之间的集成。SAS本身通常是用于文件提取,但是有了SAS/ACCESS,用户可以连接到关系型数据库(如Oracle或Teradata)和数据仓库(如Greenplum或Aster)、文件和企业应用(如SAP和Salesforce.com)。
温馨提示:投资有风险,选择需谨慎。

 +微信
+微信
 当前我在线
最快30秒解答
当前我在线
最快30秒解答
文章很精彩?转发给需要的朋友吧 
 分享该文章
分享该文章
















-
GDP半年报出炉!如何解读?下半年怎么看?
 2026-07-20 11:43
2026-07-20 11:43
-
你还在交万5的佣金?一年可能多花6000块(附省钱攻略)
2026-07-20 11:43
-
客户经理执业编号怎么查?中证协官网3步验证教程(2026最新版)
2026-07-20 11:43


