

数据科学项目当前分析架构
发布时间:2021-2-24 14:32阅读:452
 问一问
问一问1.2.2 当前分析架构
前面讲到,数据科学项目需要专门建立的工作台对数据做实验,该工作台应具有灵活和敏捷的数据架构。大多数组织机构都拥有数据仓库,用于为传统的报表和简单的数据分析行为提供良好的支持,但是不能支持强大的分析功能。本节将介绍一种企业中存在的典型的数据分析架构。
图1.9所示为一种典型的数据架构,以及数据科学家和试图进行高级分析的其他人员所面临的几种挑战。本节将讲解数据科学家所使用的数据,以及数据科学家如何融入获取数据以便在项目中进行分析的流程。
1.为了将数据源加载到数据仓库,我们要先理解数据,然后结构化数据,再使用合适的数据类型定义来标准化数据。虽然这种集中化可以为关键数据提供安全、备份和故障转移功能,但是在数据进入这种受控环境之前,必须经过大量的预处理和检查点(checkpoint)处理,这样将导致数据不适合数据探索和迭代分析。
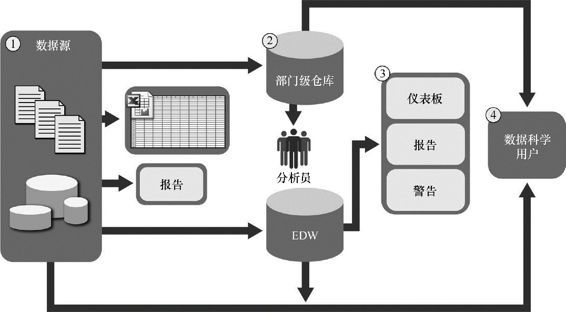
图1.9 典型的分析架构
2.由于EDW对数据的严格控制,商业用户往往为了适应灵活的分析需求而创建额外的部门仓库和本地数据集市。这些本地数据集市可能没有与主EDW一致的安全性和结构的约束,从而允许用户进行更深入的分析。但是,这些本地系统通常处于孤立状态,不会保持相互间的数据同步或者与其他数据存储进行集成,甚至可能没有进行备份。
3.进入数据仓库后,数据将被企业中的应用程序读取,以便进行商业智能分析和报告。这些都是从数据仓库和储存库中获取关键数据的高优先级业务操作流程。
4.在工作流结尾部分,分析员获得用于下游分析的数据。因为用户一般不能在生产数据库中进行自定义或者密集的数据分析,数据分析员会从EDW中提取数据,然后使用R或者其他本地分析工具进行离线数据分析。很多情况下,这些工具是对数据样本进行内存分析,而不是对整个数据集进行分析。因为这些分析是基于从EDW提取的数据并且在EDW外进行,所以分析的结果以及任何与数据质量和异常相关的洞察,都极少被反馈回主数据存储库。
由于严格的验证和数据格式化,导致EDW中新的数据源积累的速度很慢,数据移到EDW的速度也很慢,这样导致数据模式的变化也很慢。部门级数据仓库(Departmental data warehouses)在最初可能只是针对特定的目的和业务需求而设计,但随着时间的推移,部门数据仓库内的数据越来越多,其中一些数据可能被强制转换成现有的模式,以启用商业智能并创建OLAP数据库进行分析和报告。虽然EDW实现了生成报表的目标,有时还能创建仪表盘(Dashboard),但大多数情况下EDW限制了分析员在一个独立的非生产环境中迭代地进行深入的数据分析或者对非结构化数据进行分析的能力。
上述的典型数据架构是为存储和处理关键任务数据,支持企业级应用程序,并可以生成公司报表而设计的。尽管报表和仪表盘(Dashboard)对于企业仍旧非常重要,但是大部分的传统数据架构抑制了数据探索和更复杂的数据分析。另外,传统数据架构对于数据科学家还有额外的影响。
- 高价值的数据很难被获取和使用,预测分析和数据挖掘被视为数据应用的末等环节。因为EDW是专为集中数据管理和报告而设计的,一般情况下获取用于分析数据的操作被冠以较低优先级。
- 数据从EDW被批量移动到本地分析工具。该流程意味着数据科学家只能进行内存分析(比如,使用R、SRA、SPSS,或者Excel),这将限制他们可以分析的数据集规模。因此,分析可能会受到数据采样的约束,这样将影响到模型的精度。
- 数据科学项目通常是即席的和孤立的,而不是被集中管理的。这种孤立意味着组织机构不能可扩展地利用先进的分析方法,并且数据科学项目经常无法与公司业务目标或战略保持一致性。
相比数据能被持续快速访问以及进行高级分析的环境,传统数据架构的这些症状导致了缓慢的从数据到洞见的过程和较低的商业影响力。 之前提到,引进分析沙盘是解决这个问题的方法之一,它可以让数据科学家在受控和批准的方式下进行高级数据分析。同时,当前的数据仓库解决方案可以继续提供报表和商业智能服务,以支持管理和关键任务操作。
1.2.3 大数据的驱动力
为了能够更好地了解与大数据相关的的市场驱动力,我们首先需要了解数据存储的历史、各种存储库和管理数据存储的工具。
如图1.10所示,在20世纪90年代,信息量经常以TB为单位测量。大多数组织机构以行和列的方式结构化和分析数据,使用关系型数据库和数据仓库来存储管理大量的企业信息。在接下来的10年,我们看到各种类型的数据源的增长,数据量也激增到PB级别的规模,这些数据主要通过内容管理系统和网络存储系统等生产力工具进行管理。到2010年,每个人和每件事都会留下数字足迹,而组织机构需要管理许多其他类型的数据信息。图1.10概括了新应用所产生的大数据,以及数据增长的规模和速度。这些应用所产生的数据量都是EB量级,给企业带来了新的分析和挖掘数据新价值的机会。这些新的数据源包括:
- 医疗信息,如基因组测序和诊断影像;
- 上传到互联网上的照片和视频素材;
- 视频监控,如城市中分布的成千上万的摄像头;
- 移动设备,它会产生用户的地理位置数据,还有短信数据、电话记录,以及智能手机上应用程序的使用情况。
- 智能设备,包括智能电网、智能建筑等公共和基础设施中传感器采集的信息。
- 非传统IT设备,包括使用的无线电频率识别(RFID)阅读器、GPS导航系统和地震信息处理。
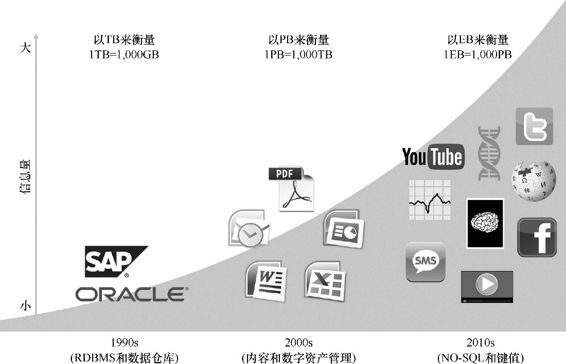
图1.10 数据的演变和大数据源的增长
未来,大数据中越来越多的数据源将产生大量的信息,这些海量的数据都需要高级的分析方法,也需要新的市场玩家来利用这些机会和新的市场动态,下一节将详细讨论。
1.2.4 新的大数据生态系统和新的分析方法
由于组织机构和数据收集者意识到个人数据中蕴含着巨大的价值,所以就出现了一种新的经济。随着新兴数字经济不断的发展,市场就出现了数据厂商和数据清洁服务商。数据清洁服务商使用众包(比如,亚马逊Mechanical Turk平台和GalaxyZoo平台)的方式来测试机器学习技术的成果。此外,其他一些数据厂商对开源工具简单重新打包并增加附加价值,然后将这些工具拿到市场上销售。Cloudera、Hortonworks和Pivotal这些厂商就是在开源框架Hadoop的基础上提供增值服务。
随着新的大数据生态系统初步成型,这其中有4种主要的生态参与者,如图1.11所示。
-
数据设备[如图1.11中第1部分所示]和“传感器网络”从多个位置收集数据,并不断产生与这些数据相关的新数据。针对所收集的每GB(gigabyte)数据,最终大约会额外产生 1个PB(petabyte)大小的关于这些数据的新数据[2]。
- 例如,当人们使用PC、游戏机或智能手机玩在线视频游戏时,视频游戏提供商会抓取游戏玩家的技能和等级相关数据,并通过智能系统监控并记录用户玩游戏的时间和方式。通过利用这些用户数据,游戏提供商可以细调游戏难度,向用户推荐可能会感兴趣的其他相关游戏,以及根据用户的年龄、性别和兴趣为游戏角色提供额外的装备和优化。这些用户信息可以存储在本地或者上传游戏提供商的云上,用来分析用户的游戏习惯和识别特定用户属性,从而增大增值销售和追加销售的机会。
- 智能手机提供了另一种丰富的数据源。除了基本的短信息和通话功能,智能手机还可以存储和传输用户上网、使用短信息和实时位置等元数据信息。当用于路况分析时,乘车者的智能手机产生的元数据信息可以用来分析追踪汽车的行驶速度或者繁忙路段的交通拥挤情况。通过这种方式,车载GPS设备可以为司机提供实时路况更新,并提供替代路线以躲过拥堵路段。
- 零售商场办理的会员卡不只记录了消费者每次的消费金额,还会记录顾客每次访问的商店位置、购买商品的种类、最常购物的商店以及一起购买的商品组合。通过收集这些数据可以洞悉用户的购物和旅行习惯,以及判断特定促销广告是否会奏效。
-
数据收集器[如图1.11中第2部分标记的椭圆形]包括从设备和用户那里收集数据的样本实体。
- 有线电视供应商,他们收集的数据包括用户的观看记录、用户会和不会付费观看的点播电视频道,以及用户愿意花多少钱观看优质节目内容。
- 零售商店,通过购物车中带有的RFID芯片追踪消费者的购物路线,利用RFID芯片中收集的地理空间数据可以分析出哪些商品吸引了最多人驻足关注。
- 数据整合者(如图1.11中第3部分标记的椭圆形)利用“传感器网络”或“物联网”收集的数据创造价值。这些组织机构汇总和解析设备数据和由政府机构、零售商店和网站等收集的设备使用信息,然后将数据转换和打包成产品出售。比如可以出售给中间商,后者再利用这些数据锁定特定市场广告营销的目标受众。
-
数据使用者和购买者(如图1.11中第4部分所示)直接受益于数据价值链中其他人收集和汇总的数据。
- 零售银行会想要了解哪些客户群体最有可能申请二次抵押或者房屋净值信用额度。为此,零售银行可以从数据整合者手里购买相关数据用于上述分析。这类数据可能包括生活在特定区域的人口统计情况;负担一定债务的人群,这些人群拥有可靠的信用评分(或者其他特征,比如能够按时支付账单和拥有储蓄账户),可以确保放贷的安全;通过搜索网站查找清偿债务或者房屋改造项目等相关信息的人群。在大数据出现之前,上述精准市场营销行为由于缺乏信息和高性能技术而面临诸多挑战。 而现在,一切变得可能。
- 人们可以通过Hadoop这类技术对社交媒体网站上的非结构化和文本数据进行自然语言分处理,来预测公众对总统竞选之类事件的反应。比如,人们可以通过分析相关博客和线上评论来了解公众对候选人的态度。类似地,人们可以通过分析社交媒体上的讨论来判断受飓风影响的区域和飓风的移动轨迹,以便追踪和防范自然灾害的发生。
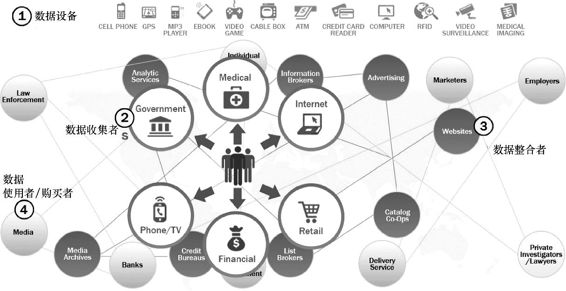
图1.11 新兴的大数据生态系统
在这个新兴的大数据生态系统中,数据类型和相关的市场动态变动极大。这些数据集包括传感器数据、文本文件、结构化数据集和社交媒体数据。如果在传统EDW中,这些数据集将无法被处理,因为EDW主要用于简单报表、仪表盘和集中管理。因此,大数据相关的问题和项目需要使用不同的方法来处理。
分析员需要与IT部门、DBA的配合才能获得分析沙盘需要的数据。一个典型的分析沙盘包括原始数据、聚合数据和多种结构类型的数据。沙盘使强大的数据勘探变得可能,但是需要有经验的用户来使用和发挥沙盘环境中的数据优势。
温馨提示:投资有风险,选择需谨慎。

 +微信
+微信
 当前我在线
最快30秒解答
当前我在线
最快30秒解答
文章很精彩?转发给需要的朋友吧 
 分享该文章
分享该文章
















-
想换券商又怕麻烦?转户全流程拆解:不用先销户,资产转移比你想象的简单
 2026-07-13 10:11
2026-07-13 10:11
-
104天过会、估值420亿:宇树科技凭什么成为"人形机器人第一股"?
2026-07-13 10:11
-
本周打新日历:2026年A股规模最大IPO【长鑫科技】即将发行!一键速览重点
2026-07-13 10:11


